


Key Takeaways
- Enterprise AI-infused systems often fail in production because inference is treated as a sidecar, not a core capability.
- Enterprise AI-first architecture means designing around reasoning—not retrofitting it into legacy systems.
- Payers need semantic data layers, token-aware orchestration, and stateful inference to ensure safe, repeatable outputs.
- System behavior becomes traceable when prompt lineage, model logic, and output context are logged and versioned.
- Migration to Enterprise AI-first starts small: fix the high-risk logic paths first, then expand once outputs hold under scrutiny.
Remember when McDonald’s rolled out AI at the drive-thru only to have it confidently process an order for 260 Chicken McNuggets after mishearing “two thirty nuggets”? That’s not just a funny mistake. It’s a preview of what happens when AI-infused systems get deployed without context control, input orchestration, or behavior observability.
Payer organizations are now walking the same line.
You’ll find LLMs layered over portals, denial letter generation tools bolted to brittle workflows, and API wrappers that summarize policy text without understanding intent. These are classic AI-infused systems retrofitted, disconnected, and ill-equipped to handle dynamic inference.
The issue isn’t that AI doesn’t work. It’s that inference has no first-class role in the stack.
In AI-infused architectures, reasoning is a sidecar process: no vector-native schema, no token-aware API routing, no persistent semantic context. Which means no stability, no traceability, and ultimately—no trust.
By contrast, AI-first systems are engineered around intelligence. LLM inference isn’t just integrated—it’s the operational core. Everything else orbits around it.
For payer infrastructure, that shift shows up as:
- Embedding semantic representations directly into the data layer
- Orchestrating prompt routing through context-aware APIs
- Designing user interfaces that adjust dynamically based on token flow and system confidence
- Implementing full inference lineage and observability across every interaction
This isn’t just a change in tools—it’s a shift in architecture, mindset, and control. And in regulated domains like healthcare payers, where hallucinated outputs and brittle integrations carry financial and legal weight, that shift isn’t optional.
It’s already happening. The only question is whether you’ll retrofit to catch up—or rebuild to lead.
Why AI-Infused Systems Break in Production
AI-infused systems break in real workflows because inference is bolted on, not built in. Stateless prompts, blind routing, and lack of semantic data architecture lead to unpredictable outputs and audit risk. Fixing it requires rethinking system design—not just better tooling.
Most AI deployments fail in production because legacy architectures can’t support intelligent behavior. Without context memory, semantic retrieval, or governed inference, LLMs go off-script. Payers need systems that treat reasoning as infrastructure, not a sidecar.
It’s easy to deploy an LLM. Harder to operationalize one. And nearly impossible to do it well inside an architecture that was never meant to reason.
Most AI-infused applications look fine on the surface. A plan explainer. A chatbot. A summarizer that sits on top of a claim. But once you move beyond the prototype—once tokens start flowing through actual workflows—the seams show.
Inference lives at the edge of the system. Context is missing. Output is unstable. And no one can explain why.
This isn’t a tooling issue. It’s architectural.
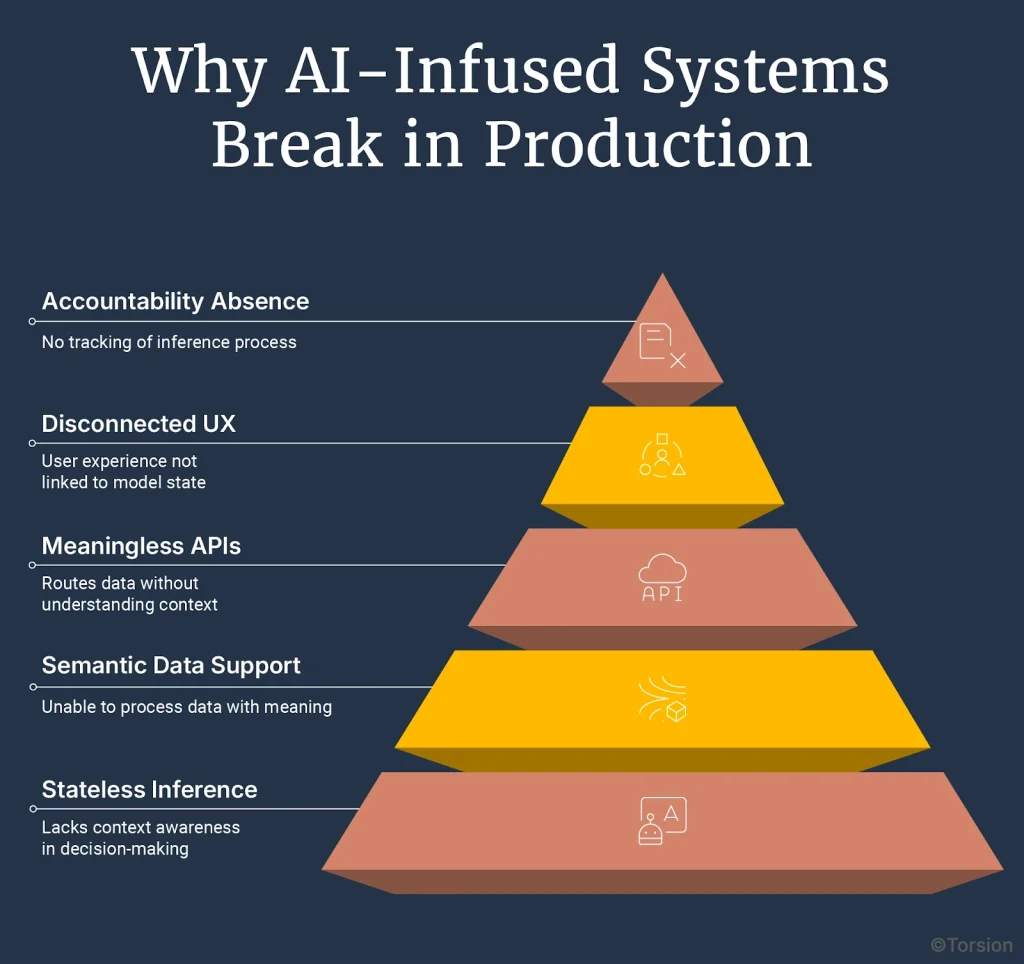
Breakdown 1: Inference is stateless and context-blind
Requests are treated as atomic. Each call reconstitutes the prompt from scratch. No memory. No feedback loop. No notion of conversation. Just fragments.
Breakdown 2: The data layer doesn’t support semantic operations
Your claim adjudication engine stores structured codes, not semantic embeddings. Your member history table wasn’t designed for retrieval-augmented generation. That’s why your model struggles to synthesize across notes, tiers, and exceptions. The architecture won’t let it.
Breakdown 3: APIs route data, not meaning
There’s no token governance. No latency budget controls. No way to route based on complexity or risk. You’re treating inference like a static microservice call—when what you need is behavior orchestration.
Breakdown 4: UX is disconnected from model state
The interface says “real-time assistant,” but there’s no feedback mechanism. No fallback logic. No observability tied to user behavior. Which means your chatbot goes off-script—and no one catches it.
Breakdown 5: No inference lineage, no accountability
A denial gets generated. It looks correct. Until legal flags it. But by then, the context is lost. You can’t reconstruct the inputs. You can’t inspect the prompt. You can’t explain the behavior. That’s not drift—that’s exposure.
Every one of these failure points stems from the same issue: inference is outside the architecture. Treated as an add-on, not a core capability.
What AI-First Architecture Looks Like for Payers
AI-first systems treat inference as infrastructure. For payers, this means semantic data layers, token-aware APIs, and stateful, observable reasoning. It’s not about adding AI—it’s about building systems where behavior is controllable, traceable, and designed for clinical and regulatory precision.
In payer operations, AI-first architecture means designing around inference: context-carrying sessions, prompt version control, and interfaces that adapt to model confidence. It’s how intelligence becomes a system feature—not a liability.
If AI-infused systems fail because inference is external, then AI-first systems succeed by design—because inference becomes the organizing principle.
In AI-first architectures, you don’t add intelligence. You build around it.
This isn’t about “embedding AI” into apps. It’s about rethinking every layer—data, orchestration, API, UX—as if inference is your default execution model.
In a payer environment, that has immediate implications:
Data is semantic, not just structured
You don’t just store claim codes and plan tiers. You store embeddings—semantic representations of plan logic, member intent, prior case context. That allows similarity search, relevance filtering, and retrieval-augmented prompts without duct tape.
APIs are token-aware and behavior-driven
Endpoints aren’t passive. They allocate latency budgets, select models, and tune prompt parameters in real time based on query complexity, member profile, and policy domain. This isn’t call-and-response. It’s orchestration.
Inference is stateful
Sessions aren’t stateless API calls. They’re multi-turn, context-preserving, reasoning environments. When a member moves from chat to call to form, the system carries semantic memory across modalities like a human would.
The interface reflects system confidence
If the model becomes uncertain, the UI reflects it. It adapts tone. Offers clarification. Routes to human review. In an AI-first world, the front end isn’t a facade. It’s a reflection of real-time reasoning state.
Every decision is traceable
Prompt lineage, model version, embedding source, retrieval logic—everything is logged. Not for auditing after the fact, but for observability during inference. In payer systems, explainability isn’t a feature. It’s table stakes.
What Changes When You Build for Behavior
AI-first systems reduce variance, preserve context, and make decisions traceable in real time. Payers gain operational stability, adaptive reasoning, and cost control—because they’re managing behavior, not just outputs.
When payers build for behavior, systems respond with memory, context, and traceability. Output stabilizes, handoffs feel seamless, and every decision leaves a trail. It’s not AI as a tool—it’s intelligence as infrastructure.
Once you’ve seen the shape of AI-first architecture, the next question isn’t “how does it work?”—it’s “what do I actually get?”
You get systems that stop reacting and start behaving.
Most AI-infused stacks are like stage actors reading lines. They sound fluent, but they don’t know what they just said. No memory. No continuity. No judgment. In contrast, AI-first systems behave more like trained analysts. They carry forward context. They adjust based on confidence. They don’t just respond—they reason.
This shift changes how your operation feels. And how it performs.

1. Output variance goes down because inputs are governed
Prompts aren’t hand-written or improvised. They’re built from versioned fragments—retrieved policy clauses, standardized benefit logic, prior interactions. That control upstream makes the output repeatable downstream.
2. Conversations don’t reset across touchpoints
When a member moves from portal to call, the system doesn’t reintroduce itself. It knows the history. The model has access to it in token memory or retrieval context. No rephrasing. No duplicated effort. Just progress.
3. Explainability is built into inference, not layered on top
Every model response includes metadata: prompt ID, model version, context source. If something needs review, you have the full trace immediately. You don’t have to reconstruct what happened. You already know.
4. Feedback loops close themselves
When a model output is corrected by a reviewer, an agent, or a rules engine that signal feeds the next inference. No more static review queues. The system tunes itself over time.
5. Token spend stops behaving like a wildcard
Inference cost is linked to intent. Complex requests route to larger models. Routine flows run through cached prompts or smaller deployments. Finance gets visibility by use case, not just total volume.
The behavior is different because the foundation is different. You’re not managing model output, you’re managing system behavior. That’s the real unlock.
How Payers Shift Their Systems Toward AI-First Behavior
Payers move toward AI-first by upgrading high-risk workflows—one at a time. Focus on decisions that need traceability, embed orchestration to manage model behavior, and scale only when outputs are stable and auditable.
To operationalize AI-first, payer systems must evolve workflow by workflow. Prioritize areas where output drives action, add behavioral control, and replace brittle logic with governed reasoning that scales without guesswork.
If you’re already seeing consistent outputs, the next step is to extend that behavior into the rest of your system—one workflow at a time.
You don’t need to overhaul everything. You just need to replace the parts where model decisions carry weight and the logic isn’t traceable yet.
1. Focus on workflows where model output drives action
Start where the output isn’t optional.
- Denial letters that must match policy
- Prior auth summaries that go to clinicians
- Benefit explanations that members read and rely on
- Appeals that require traceable logic
If these break down, someone has to intervene. That’s where behavior needs to be controlled first.
2. Trace what creates the output, not what surrounds it
Ignore the front end. Focus on what turns data into a response.
- What information is fetched?
- How is the prompt assembled?
- What’s passed to the model?
- What logic routes the result?
Until you’ve mapped that path, you’re only adjusting symptoms—not the system.
3. Introduce orchestration that manages how the model behaves
This is where your system stops guessing.
- Retrieve the right policy language, not just any document
- Use modular prompt templates that adjust for tone or jurisdiction
- Assign model size based on complexity
- Log everything—input source, prompt ID, model version, output reason
Now inference becomes something you can see and manage—not just monitor.
4. Replace brittle pieces, not entire systems
Pick one logic path that’s failing, maybe a denial builder or a coverage explainer, and replace only that component.
- Drop static prompts
- Add fallbacks for unclear answers
- Insert routing logic tied to risk or review thresholds
Keep everything else the same. Just change the behavior layer.
5. Expand once the output holds under real pressure
Look for consistency. Are edge cases handled? Do reviewers trust the result? Does cost track to complexity?
Then extend to:
- Other workflows that share similar logic
- Other plan tiers or member segments
- More routing logic, caching, or escalation triggers
At that point, you’re not scaling a tool. You’re scaling intelligence—deliberately, and on your terms.
Why Behavior Is the Real Differentiator
Even if every payer already uses Enterprise AI, that’s not the advantage.
The real gap is between those who observe model outputs and those who shape model behavior.
Because the systems that generate explanations, route escalations, or support appeals aren’t just producing content. They’re making decisions. And decisions need to be explainable, repeatable, and aligned with policy every time.
That’s what AI-first architecture delivers. Not better models. Better control over how those models work inside your system.
The organizations that lead this shift won’t just avoid error. They’ll unlock speed, precision, and trust at scale.
Not by deploying more AI.
By designing systems that behave as well as they perform.




